
0G核心模块|存储架构设计与实现
主要内容
- 0G Storage 模块功能介绍与工作流程
- 数据可验证存储 (Proof of Random Access) 机制
- SDK 安装与使用教程 (上传/下载)
- 去中心化数据存储场景中的实际部署方案
一. 数据存储相关
原课件:
Current storage options force impossible tradeoffs:
Cloud providers: Fast but expensive with vendor lock-in
Distributed options: Either slow (IPFS)
Decentralized: Or limited (Filecoin), or prohibitively expensive (Arweave)
笔记:
当前常见的数据存储方式及问题
云服务商(Cloud providers,比如 AWS、Google Cloud、阿里云)
- 优点:速度快,使用方便。
- 缺点:价格很贵,而且容易被厂商“绑架”(vendor lock-in,意思是你用了他们的服务后,迁移到别的地方会很麻烦)。
分布式存储(Distributed options,比如 IPFS)
- 优点:去中心化,理论上不依赖单一公司。
- 缺点:速度很慢,实际体验差。
去中心化存储(Decentralized storage,比如 Filecoin、Arweave)
- Filecoin:功能有限,应用场景不够灵活。
- Arweave:存储费用非常高,很多项目承担不起。
二. 0G 的系统设计(0G 如何设计以解决上述问题)
原课件:
Log Layer (Immutable Storage)
- For AI training data, archives, backups
- Append-only (write once, read many)
- Optimized for large files
- Lower cost for permanent storage
Key-Value Layer (Mutable Storage)
- For databases, dynamic content, state storage
- Update existing data
- Fast key-based retrieval
- Real-time applications
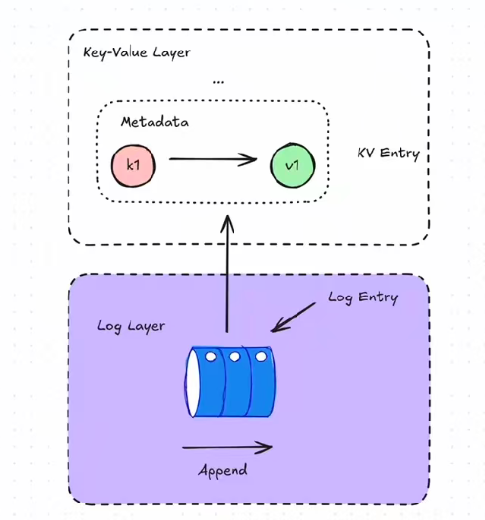
笔记:
0G 通过设计两层存储结构来兼顾速度和成本:
Log Layer(不可变存储)
- 主要用于 AI 训练数据、档案、备份
- 只允许追加写入(写一次,多次读取)
- 针对大文件进行了优化
- 适合长期存储,成本较低
Key-Value Layer(可变存储)
- 用于数据库、动态内容、状态存储
- 可以更新已有数据
- 支持基于键的快速检索
- 适合实时应用
在不可变存储(Log Layer)中,适合存放训练数据、档案和备份。这里采用“写一次,多次读”的方式,优化了大文件的存储效率,同时降低长期存储的成本。
在可变存储(Key-Value Layer)中,支持数据库、动态内容和实时应用。这里允许数据更新,并提供快速的键值检索能力,从而满足实时性要求。
通过这种分层方式,0G 既能保证速度和低成本,又避免了传统云的厂商锁定问题,也比 IPFS、Filecoin、Arweave 更灵活和实用。
日志上链有先后顺序
- 在 0G 的 Log Layer(不可变存储) 中,数据是以“追加写入”的方式存储的。
- 每条日志都有时间顺序或顺序编号(类似区块链的区块顺序),保证写入的顺序不可篡改。
- 这样即使数据量很大,也能通过顺序索引快速找到最新的数据或某个历史数据点。
天然的回滚机制
- 因为日志是按顺序追加的,如果出现错误或需要恢复到某个历史状态,只需回到某条日志之前的状态即可。
- 不像传统数据库可能需要复杂的事务和回滚操作,日志的顺序本身就天然提供了恢复历史状态的能力。
存储数据流程图:
Log Layer 的顺序写入不仅保证了数据不可篡改,还可以天然支持回滚历史状态,非常适合 AI 数据、备份等长期存储场景。
回滚流程图:
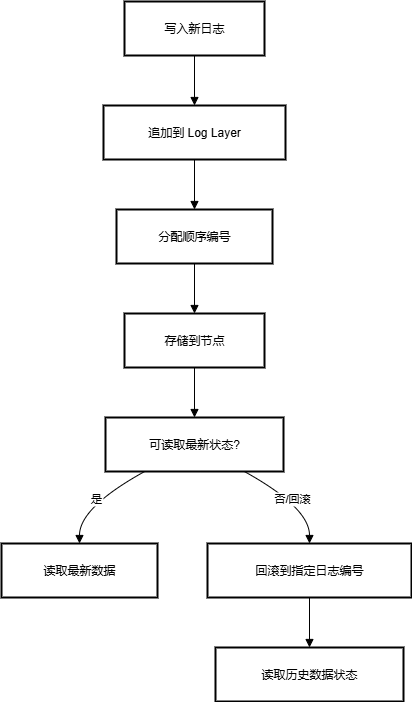
三. 实际数据上传设计
原课件:
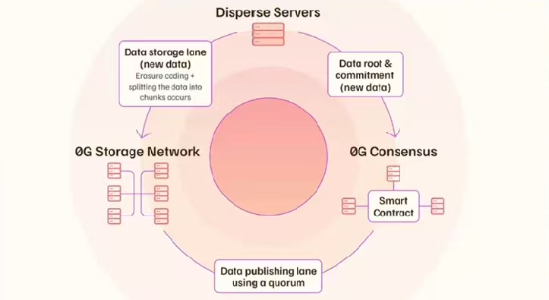
Data Publishing Lane
Handles metadata and availability proofs
Verified through 0G Consensus network
Enables fast data discovery
Data Storage Lane
Manages actual data storage
Uses erasure coding: splits data into chunks with redundancy
2.1 Even if 30% of nodes fail, data remains accessibleAutomatic replication
笔记:
Publishing Lane:负责“证明”和“发现”,保证别人能找到并信任你的数据。
Storage Lane:负责“存储”和“冗余”,保证你的数据长期可用,即使部分节点失效也不会丢失。
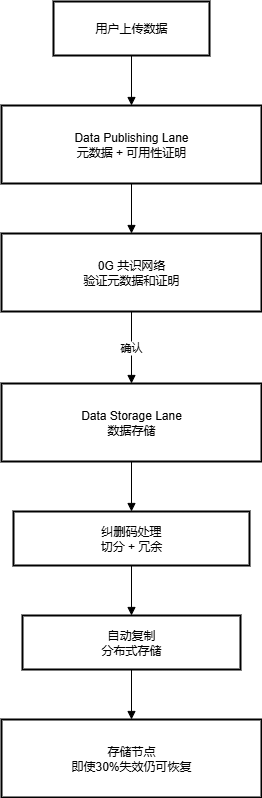
数据上传流程
第一步:数据发布 (Data Publishing Lane)
- 当用户上传数据时,系统会先处理 元数据(metadata),并生成 可用性证明(availability proofs)。
- 这些证明会提交到 0G 共识网络,用来确保上传的数据是真实存在的,而不是虚假信息。
- 通过这个过程,网络中其他节点能够 快速发现和验证数据。
第二步:数据存储 (Data Storage Lane)
- 真正的文件内容会进入存储通道。
- 系统会对数据进行 纠删码(erasure coding) 处理:
- 把文件切分成多个小块,并增加冗余。
- 即使有 30% 的存储节点宕机,数据依然可以完整恢复。
- 这些数据块会被 自动复制 并分布式存储在不同节点上,从而保证数据的高可用性和容错性。
上传数据流程图:
四. 分片存储设计
原课件:
Sharded Storage -Naturally suited for parallel computing
2 ^k
m independent storage nodes (non overlapping in stored data)
n clients, only uploading to certain nodes based on the shard config
Horizontally scalable m x bandwidth
笔记:
Sharded Storage(分片存储)设计说明
- 2^k 分片
- 数据被划分为 2^k个分片,每个分片都有独立编号。
- 这样可以更精细地分布数据,提高并行处理能力。(链上数据与链下物理块可以更好的对应,更快定位到数据位置)
- m 个独立存储节点
- 每个节点存储的数据 不重叠,保证数据均匀分布。
- 节点之间互不干扰,提高效率和容错性。
- n 个客户端上传数据
- 客户端根据 分片配置(shard config),只上传到特定的节点。
- 避免所有客户端都上传到同一节点,减少瓶颈。
- 水平扩展能力
- 可以通过增加更多节点来提升系统容量和吞吐量。
- 理论上带宽可以达到
m × 单节点带宽,实现线性扩展。
分片存储策略流程图:
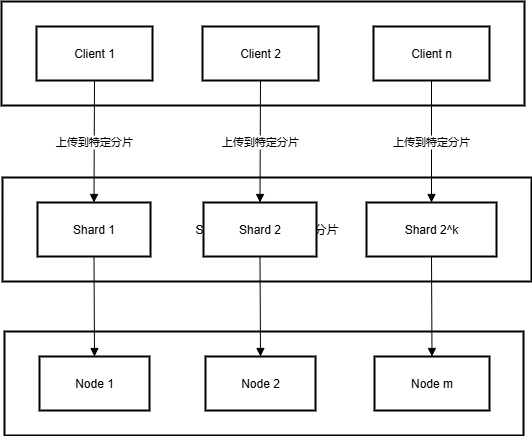
- 客户端根据 shard 配置上传数据,只上传到特定分片。
- 分片再映射到独立存储节点,节点之间数据不重叠。
- 新增节点可以水平扩展系统容量,带宽几乎线性增加。
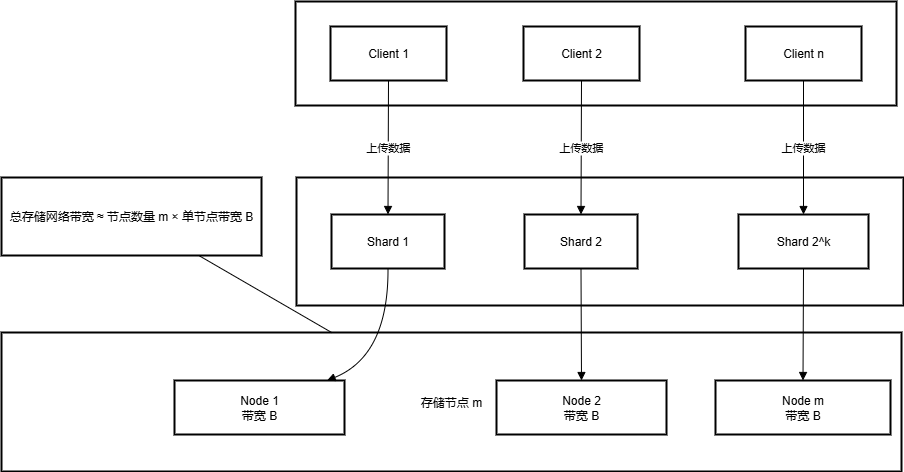
带宽的计算
1. 单节点带宽
每个存储节点都有自己的网络带宽,例如 B Mbps。
节点处理自己存储的分片时,可以利用这个带宽进行上传/下载。
2. 分片与节点
- 数据被划分为 2^k 个分片
- 分片分布在 m 个节点 上(通常 2k≥m2^k \ge m2k≥m),每个节点可能存储多个分片
- 客户端上传数据时,每个分片的数据只能上传到对应节点
3. 水平可扩展带宽
- 如果节点数量增加,系统总带宽大约线性增加
- 理论上,存储网络总带宽 ≈ 节点数量 × 单节点带宽
- 不是分片数量 × 单分片带宽,因为分片可能集中在少量节点上
总结
- 分片数量决定了并行处理能力
- 节点数量决定了系统整体带宽
- 理论上,增加节点可以线性扩展总带宽
- 增加分片只是提升并行度,不直接增加总带宽
0G Storage为何要使得数据以2^k 对齐(全选)
- A.方便链上与存储网络数据对齐
- B.方便链上交易构造
- C.方便用户上传、下载时数据定位
- D.方便分片对齐
节点、分片和带宽关系的示意图
五.Flow + Merkle Tree over Flow
原课件:
Flow
The underlying structure of storage
Continuously appended list of sectors
Merkle Tree over Flow
- Merkle Root
Speacially desighed,2^k
Submission
Several concatenated sector arrays
Each length with power of two
Strictly decrease
First length <= 8 x Last lengthMetadata
Size of original data (bytes)
Merkle root and length of each arraySubmission is always composed of several Merkle trees over the subtreeswithin the Flow, providing the Merkle root.
The user’s submission will not be excessively long
笔记:
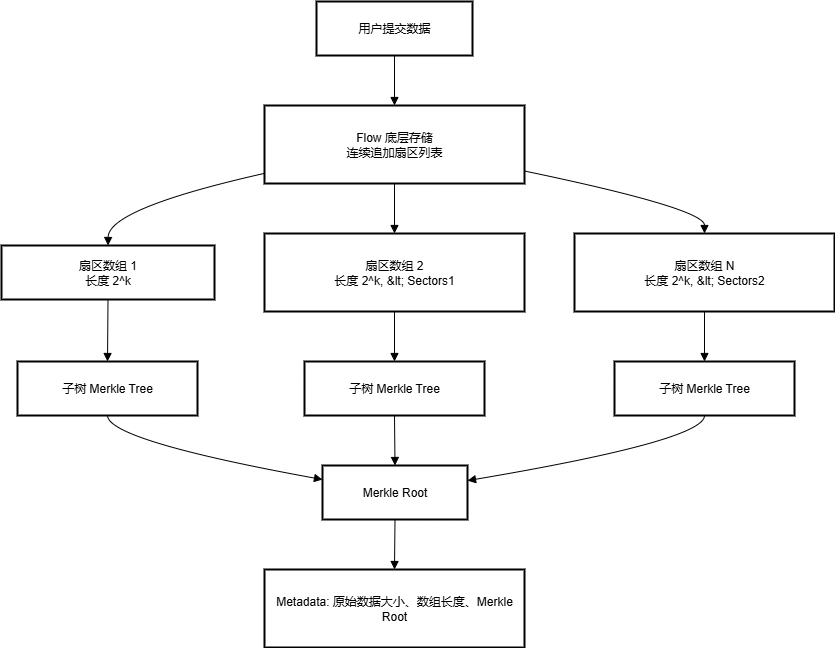
用连续追加的扇区列表作为底层存储,用 Merkle Tree 叠加验证数据完整性,同时通过长度递减的扇区数组保证提交数据高效且安全。
结构体示意:
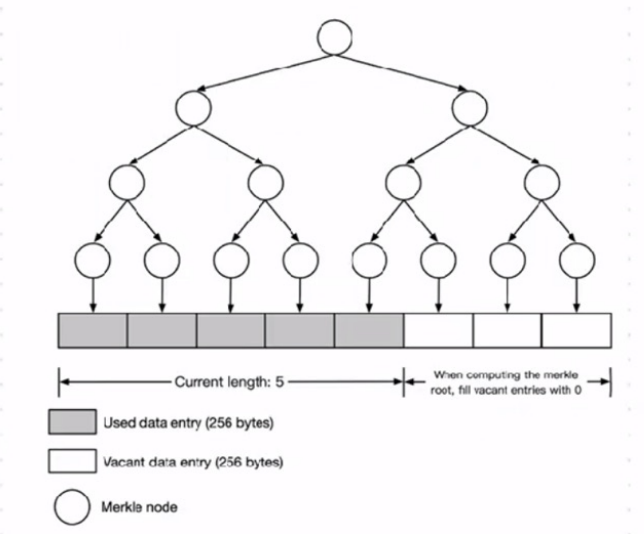
Flow(底层存储结构)
- 数据存储为 连续追加的扇区列表(sectors),类似日志追加的方式。
- 保证写入顺序不可篡改,也方便回溯历史数据。
Flow 上的 Merkle Tree
- 每个提交的数据会生成一个 Merkle 根(Merkle Root),用于验证数据完整性。
- 特别设计成 2^k 的长度,方便计算和验证。
提交数据(Submission)
- 一个提交由 多个连接的扇区数组 组成。
- 每个数组的长度是 2 的幂次方,并且 严格递减,第一个数组长度 ≤ 最后一个数组长度的 8 倍。
- 这样可以保证数据分片有规律,方便验证和存储优化。
元数据(Metadata)
- 包括原始数据大小(字节)、每个数组的长度、以及 Merkle 根。
- 用于快速验证数据完整性和定位数据位置。
Merkle Tree 的作用
- 每次提交的数据都会在 Flow 上形成 若干子树的 Merkle Tree,再由这些子树生成最终 Merkle 根。
- 这样用户提交的数据既不会太长,也能高效验证完整性。
示意图:
六. PoRA _0G 的存储安全性和访问验证机制
原课件:
What if a node does not store the data but only query others’ when needed?
Data Sealing
Designed to be more expensive than simply storing therdata
1 | sealed[0] = unsealed[e] ^ keccak256(minerId, contextDigest,index) |
Sequential sealing and parallel unsealing
Unique consensus mechanism known as Proof of Random Access (PoRA)
- Random Challenges: System randomly asks miners to prove they have specific data
- Cryptographic Proof: Miners must generate a valid hash (like Bitcoin mining)
- Quick Response: Must respond fast to prove data is readily accessible
- Fair Rewards: Successful proofs earn storage fees
- Not always working, release mining context by contract periodically
- Unbounded by target submission count for each context
Recall Range
Determined by
Onchain seeds
Index of start sector——————–Miner Defined
Mining length
Difficulty Adjustment
Pora target, the higher the easier
1 | expectedPoraTarget = poraTarget * actualBlocks /TARGET BLOCKS |
笔记:
1. 数据封装(Data Sealing)
设计目的:比简单存储数据更昂贵,确保节点不能只“懒惰”地不存数据,只在需要时查询别人的数据。
封装方式:
1
2sealed[0] = unsealed[e] ^ keccak256(minerId, contextDigest,index)
sealed[i] = unsealed[i] ^ keccak256(sealedi-1])逻辑:
- 数据是 顺序封装(sequential sealing),保证每块数据依赖前一块。
- 解封(unsealing)可以 并行进行,方便验证。
2. Proof of Random Access (PoRA)
核心思想:随机挑战存储节点,确保它们真正存储了数据,而不是仅仅查询别人。
- Random Challenges:系统随机要求节点证明它们拥有某块数据
- Cryptographic Proof:节点必须生成有效的哈希证明(类似比特币挖矿)
- Quick Response:节点必须快速响应,证明数据随时可访问
- Fair Rewards:成功证明的节点获得存储费用奖励
- Periodic Mining Context:验证不是一直进行,而是周期性释放上下文
- Unbounded Target:每个上下文的目标提交次数不固定
3. Recall Range(回溯范围)
- 确定依据:
- 链上随机种子(Onchain seeds)
- 起始扇区索引(Miner Defined)
- 挖矿长度(Mining length)
- 作用:规定节点需要证明哪些数据块可访问,增加随机性和安全性
4. Difficulty Adjustment(难度调整)
目标:保证 PoRA 证明的难度适中,既不能太容易,也不能太难。
公式:
1
2
3expectedPoraTarget = poraTarget * actualBlocks /TARGET BLOCKS
poraTarget += (expectedPoraTarget -poraTarget) / ADJUST RATIO逻辑:根据实际区块产出情况动态调整 PoRA 难度
总结
这个系统设计 确保节点不能偷懒或作弊:
- 通过 Data Sealing,存储成本高、依赖顺序
- 通过 PoRA 随机挑战,验证节点随时可访问数据
- 通过 Recall Range 和 Difficulty Adjustment,保证系统安全、公平、可扩展
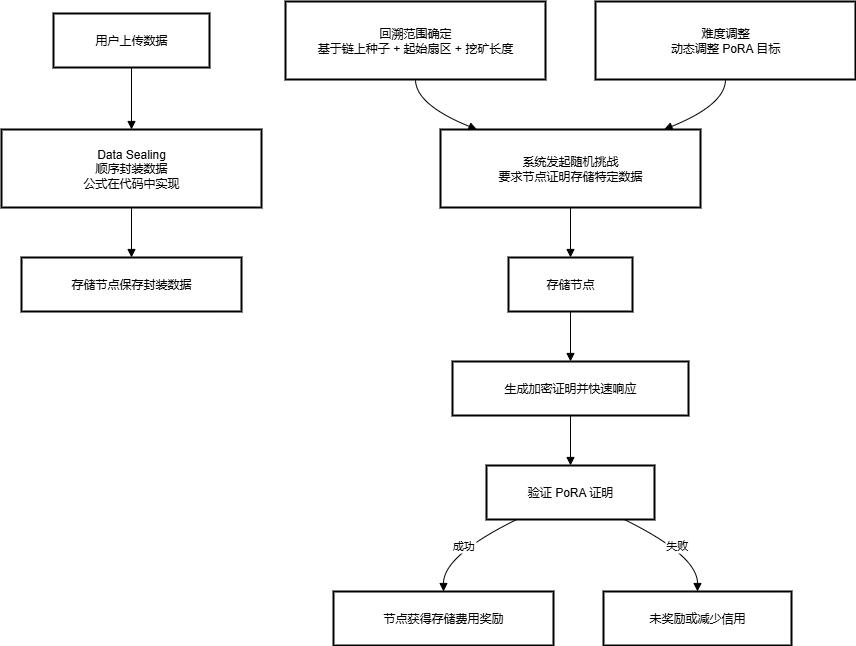
1. 初始存储位置在 Flow 的哪里?
- 用户上传的数据 先存储在 Flow 的底层结构(Flow 底层扇区列表)。
- Flow 是一个 连续追加的扇区列表(Append-only sectors),保证写入顺序不可篡改。
- 数据在 Flow 中被划分成 多个扇区数组(数组长度为 2 的幂次方,严格递减),每个数组会生成 子树 Merkle Tree,最终形成整个提交的 Merkle 根。
- 总结:初始存储在 Flow 的 连续扇区 + 扇区数组 + 子树 Merkle Tree 结构里。
2. 挖矿有难度调整,什么越高越简单?
在 0G 的 PoRA 挖矿中,系统会根据实际出块情况 动态调整难度(Difficulty Adjustment):
1
2expectedPoraTarget = poraTarget * actualBlocks / TARGET_BLOCKS
poraTarget += (expectedPoraTarget - poraTarget) / ADJUST_RATIOporaTarget 越高 → 难度越低 → 挖矿越简单
逻辑:如果系统发现节点太难完成挑战,就提高 poraTarget,让挑战更容易;如果太容易,就降低 poraTarget,让挑战更难。
3. 只挖一部分指的是什么?
- 节点并不是必须验证或提交全部存储数据,而是 随机挑战下只证明部分数据的可访问性。
- 这对应 PoRA 的随机抽查机制(Random Challenges):
- 系统随机抽取存储的某些扇区,节点需要快速生成加密证明。
- 节点只验证这一部分数据,不必全部扫描,提高效率。
- 总结:只挖一部分 = 节点只针对被系统随机抽取的数据块进行挖矿/证明,而不是整份存储数据。
4. 0G Storage 的挖矿机制里,每次挖矿数据(Recal Range)由什么因素确定(多选)
A.链上种子
B.用户存储起始位置
C.用户设置区间长度
D.网络框架规定的区间限制
全选
七. 奖励机制
Fair Competition = Fair Reward
To promote fairness, the mining range is capped at 8 TB of data per mining operation
Small miners can compete with large operations
Prevents centralization
Lower barrier to entry
Move onto next data chunk if the current is fully mined (no more rewards)
For large operators: Run multiple 8TB instances.For individuals: Focus on single 8TB range, still profitable
Pricing
sector_price x
Reward Bucket
capped at 8TB
Linear release
System Reward
0G issuing
Base reward for each PoRA, for early contributors
Service Fee
Charged by 0G
Proportion of storage fee
笔记:
1. 公平竞争(Fair Competition)
- 目的:让小矿工也能和大矿场公平竞争,防止中心化。
- 做法:
- 每次挖矿操作的 数据范围上限为 8TB。
- 小矿工可以专注单个 8TB 数据块,大矿工可以同时运行多个 8TB 实例。
- 如果当前数据块已挖完(奖励用完),就移动到下一个数据块。
- 好处:
- 降低进入门槛,小矿工也能参与。
- 避免大矿工垄断整个网络。
- 系统资源分配更均衡。
2. 奖励机制(Reward)
- Sector 奖励:每个扇区根据
sector_price × 扇区数量计算奖励。 - 奖励池(Reward Bucket):
- 每次挖矿的数据范围上限 8TB
- 奖励 线性释放,挖多少算多少
- 系统奖励(System Reward):
- 由 0G 发放
- 包括 PoRA 挖矿的基础奖励
- 鼓励早期贡献者
- 服务费(Service Fee):
- 由 0G 收取
- 按存储费用的一定比例抽取
3. 总结
- 公平竞争 + 奖励上限:防止大矿工垄断,让小矿工也能赚到奖励。
- 定价 + 奖励机制:结合扇区数量、PoRA 挑战和服务费,实现经济激励和网络可持续运行。
- 机制灵活性:大矿工可以多实例操作,小矿工集中单个数据块,也都能盈利。
八. 实现
原课件:
Core Components
0G Storage Node (For node runners)
0G Staraae Contracts (For data upload tx, mining check and reward)
0G Starage Client -Golang (For user uploaddownload operations)
0G Starage Ts SDK -TS
RPC supported
Gateway
JSON RPC
gRPC (Faster with less data overhead)
Tested with 2GB/s Upload/Download speed with 32 storage nodes (32 shards)
笔记:
1. 核心组件(Core Components)
- 0G Storage Node:运行存储节点的程序,负责存储数据和响应 PoRA 挑战。
- 0G Storage Contracts:链上智能合约,处理上传交易、挖矿验证和奖励发放。
- 0G Storage Client - Golang:用户端工具,用于上传和下载数据。
- 0G Storage TS SDK - TypeScript:提供给前端或 JS/TS 项目使用的 SDK。
2. 支持的 RPC 协议
- Gateway:网关接口,方便客户端访问存储网络。
- JSON RPC:通用的远程调用接口。
- gRPC:高性能远程调用,数据开销更小。
- 性能测试:32 个分片节点情况下,上传/下载速度可达 2GB/s。
3. 数据上传/下载流程
- 发送请求给 index
- 用户客户端先向索引服务(index)发请求,获取存储节点信息和分片配置。
- 选择相近节点进行上传/下载
- 根据网络拓扑或节点距离(latency)选择合适节点,提高传输效率。
- 链上同步交易
- 上传操作会同步到智能合约上,记录交易信息、存储证明等。
- 与同步到的节点传输数据
- 客户端与选定节点之间直接传输数据,支持广播或请求方式上传/下载。
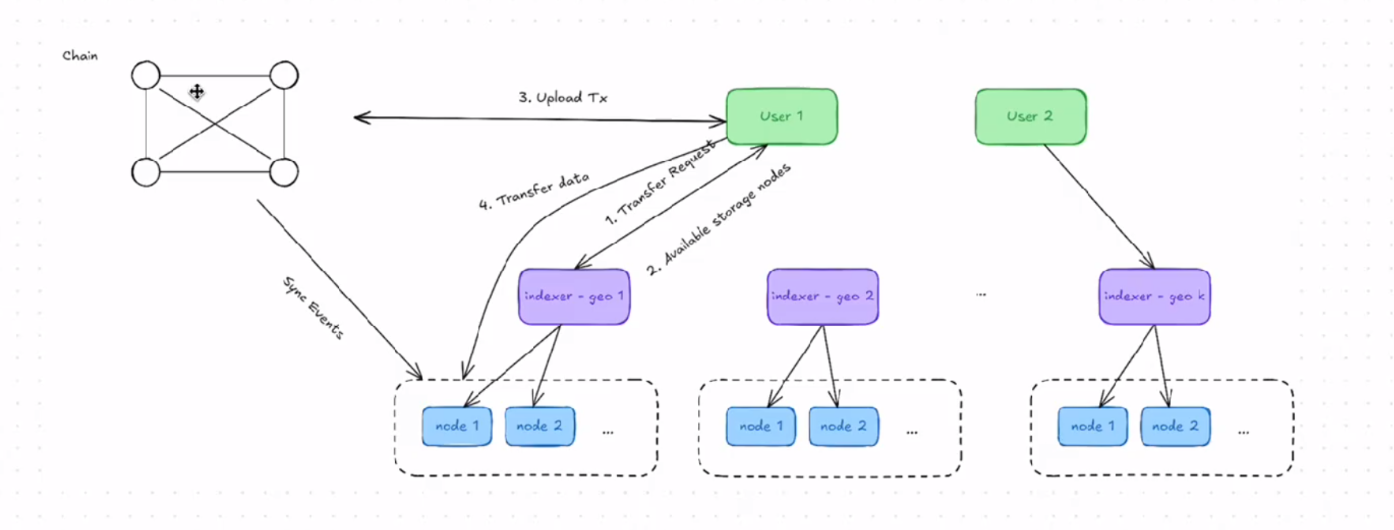
- 0G 的存储系统通过 节点 + 合约 + 客户端 + SDK 构成完整生态。
- 上传下载是 客户端 -> 索引 -> 节点 -> 链上同步 -> 节点间传输 的流程。
- 支持高性能 RPC,保证分片并行传输和大文件高吞吐。

特别的参数举例
- Provider either indexer or node list
Node list needs to cover the enti’e shards
Or indexer will do it for you
- Skip tx if you paid already but try to re-upload
- Default fee is for 3 months
- storage(minimum),set higher to store longer
- The large file will be fragmented to 4GB each.will receive a list of data roots for retrieval
Usage:
0g storagc clicnt upload
Flags–cxpected-replica uint expccted number of replications to upload (defauit 1)
–fee float fee paid in a0gi
–file string File name to upload
–finality-required Wait for file finality on nodes to upload
–fragment-size int the size of fragment to split into when file is too large (default 429
–grpe node strings ZeroGStorage storage nade gRPC URL
-h,–help help for upload
–indexer string ZeroGStorage indexer URL
–key string Private key to interact with smart contract
–max-gas-price uint max gas price to send transaction
–method string method for selecting nodes, can be max, min, random, or positive will fail if the reguirement cannot be met (default “min”)
–n-retries int number of retries for uploading whan it’s not gas price issue
–node strings ZergGStorage storage node URL
–nonce uint nonce of upload transaction
–routines int
–skip-tx Skip sending the transaction on chain if already exists (default true)…
补充
什么是并行计算
- 并行计算(Parallel Computing)就是 把一个大的计算任务分成很多小任务,同时由多个处理单元(CPU、GPU 或节点)一起处理。
- 目标是 加快计算速度,提高效率,而不是一个一个顺序执行。
并行计算是怎么工作的
- 任务分解(Task Decomposition)
- 将大任务拆成多个小子任务。
- 这些子任务尽量互相独立,避免互相等待。
- 分配到处理单元(Task Scheduling)
- 小任务被分配到不同的处理单元(CPU 核心、GPU 核心、节点等)。
- 每个处理单元同时运行一个或多个小任务。
- 独立执行(Independent Execution)
- 各个处理单元同时进行计算。
- 在 0G 的分片存储场景中,比如不同分片的数据可以在不同节点上同时存储和检索。
- 结果合并(Result Aggregation)
- 小任务完成后,把结果汇总成最终结果。
- 确保计算正确性和完整性。
举例
假设你要计算 1000 个数字的平方和:
- 顺序计算:一个数字算一个数字 → 总时间长。
- 并行计算:把 1000 个数字分成 10 组,每组 100 个数字交给 10 个 CPU 核心同时计算 → 大幅减少总时间。
在 0G 存储中的应用
- 数据被 分片(Sharding) → 每个分片可以在不同节点上并行处理上传、存储、检索。
- 并行计算提高了 上传速度、数据处理能力和吞吐量,让系统可以支持大量用户同时操作。
eliza了解
ai agent





