
aboutRAG
RAG的定义
给定知识库,从知识库中检索出合适的参考内容,让大模型据此回答。
AI客服|政策查询|AI搜索
RAG(Retrieval-Augmented Generation)是将检索外部知识库与大语言模型(LLM)生成相结合的技术,核心是让LLM基于精准的参考知识回答问题,避免幻觉。
简易流程
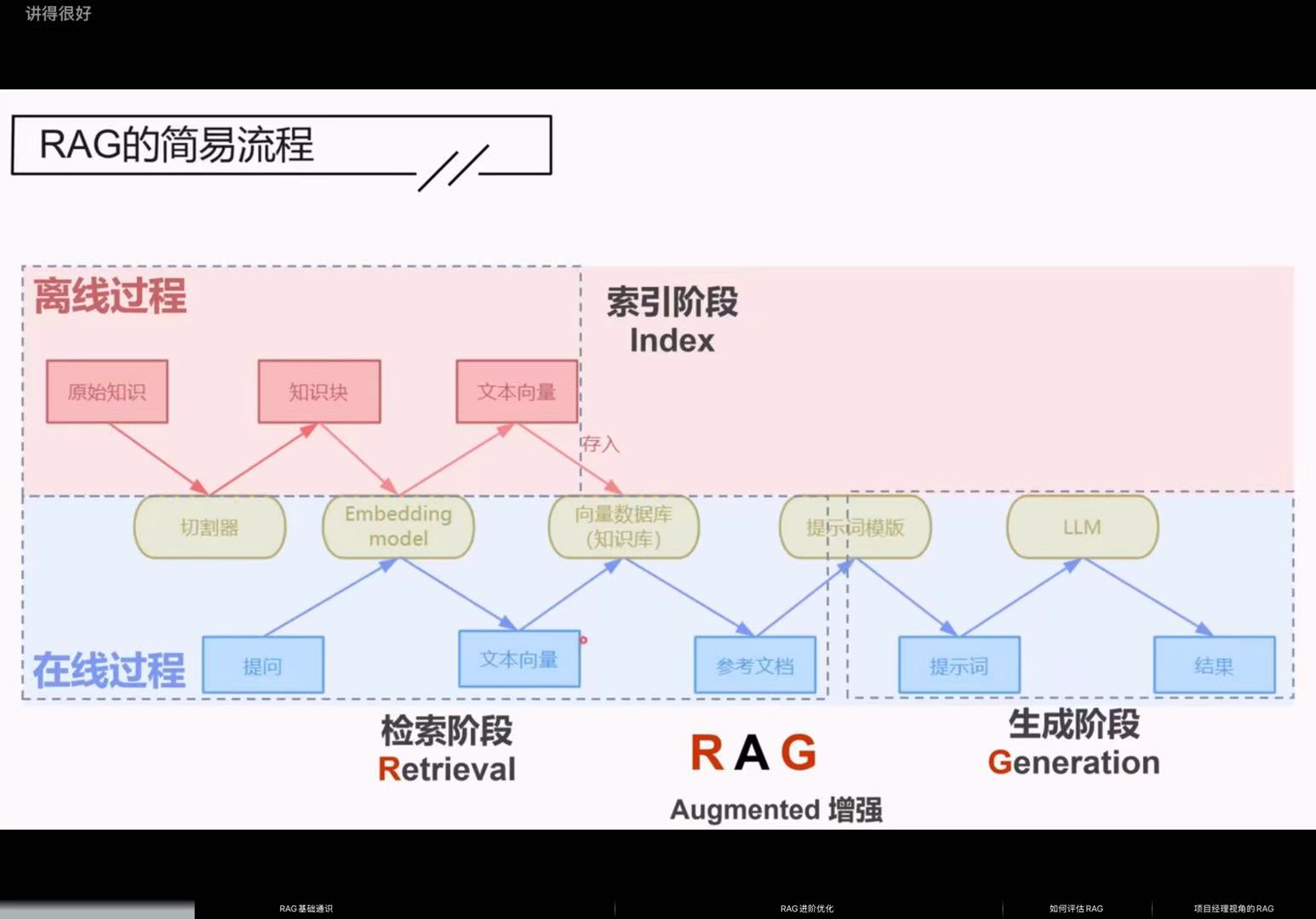
简易流程可分为知识库构建(离线阶段) 和问答推理(在线阶段) 两大核心环节,具体分点详解如下:
一、知识库构建阶段
(离线准备,核心是将原始知识转化为可检索的向量数据)
该阶段为后续问答提供数据支撑,完成后知识将以向量形式存储在数据库中,具体步骤:
原始知识输入
准备需要用于问答的基础信息(如产品保修条款、专业文献、行业资料等),作为RAG流程的数据源。切割器处理:生成知识块
利用切割器将海量、完整的原始知识拆分为大小适中、逻辑独立的知识块。
◦ 作用:解决原始知识篇幅过长、无法被模型高效处理的问题,让检索更精准。
- Embedding模型处理:生成文本向量
将拆分后的知识块输入Embedding(嵌入)模型,模型会将非结构化的文本知识转化为计算机可识别的数值型文本向量(如示例中的[0.2,0.5,0.6……])。
◦ 核心逻辑:文本向量能通过数学方式表征语义,语义越相近的文本,向量相似度越高。
- 存入向量数据库
将生成的文本向量与对应的知识块关联,统一存入向量数据库,形成可供检索的“知识库”,完成离线阶段的全部准备。
二、问答推理阶段
(在线交互,核心是基于用户提问匹配知识并生成答案)
该阶段是用户实际使用RAG的过程,从接收提问到输出结果,步骤环环相扣:
接收用户提问
获取用户的自然语言问题(如示例中的“手机可以保修多久”)。提问向量化处理
将用户提问输入同一Embedding模型,生成与知识库格式一致的提问文本向量(如[0.2,0.5,0.6……])。
关键要求:必须使用与知识库构建时相同的Embedding模型,确保向量语义空间一致,才能准确匹配。
向量数据库检索:获取参考文档
向量数据库根据提问文本向量,通过“相似度计算”检索出语义最匹配的知识块,将这些知识块作为参考文档(示例中为包含保修期限的相关条款)输出。提示词模版填充:生成提示词
将用户问题与参考文档按照预设的提示词模版进行组合,生成标准化的提示词。
◦ 模版示例:“请基于参考材料回答问题,如果不知道就答复‘暂不清楚’。问题:手机保修期是多久。参考资料:1.…… 2.…… 3.……”
◦ 作用:约束LLM的回答逻辑,强制其仅基于检索到的参考文档输出结果,杜绝幻觉。
- LLM生成:输出最终结果
将填充好的提示词输入大语言模型(LLM),模型结合参考文档的信息进行推理、整合,最终输出精准的自然语言答案(如示例中的“可以保修五年”)。
准备知识库
1.收集知识
1.1 知识存储位置
1.2 数据的格式
1.3 数据清洗
2.文档切分
根据知识库来定
保证文本语义统一(不要太长),完全(不要太短)。
- 固定大小切分(token数)
- 按照标点符号(如:换行符)
- 按照文档结构(标题、章节)
- 按照语义划分:将句子按相关性合并成段落。
3.文本向量转换
目的:计算机处理文字
- 去重词袋法(有为1,无为0)
- 不去重词袋法(数字为出现数量)
tf-idf:词的数值用特定公式计算
向量:
稀疏向量:向量中大部分都是0的向量
稠密向量
词嵌入方法(维度表示文字)——有点:语义相关性捕捉得更好
Embedding model
4.向量数据库
使用: 构建知识库时,直接存储文本,则向量数据库会使用默认的向量模型(可以个人指定)将文本向量化,然后存入数据库。然后可以实现相似度分析。
常见数据库:Chromadb FAISS等
检索
1. 基于文本相似度的检索

余弦相似度能够更好地理解语义,挖掘用途,容错率更高。
2. 基于关键字的检索
- 构建 关键词&对应文档 的映射表
- 应用
命中率高,适用于准确文档准确提问
生成
- 提示词构造
1 | 请基于参考资料回答问题,如果不知道就直接答复“不清楚” |
- 模型
- 自行部署:开源
- 调用外部接口:闭源
RAG进阶优化
检索优化的技巧
small to big
摘要检索
主要是用大模型处理总结文本摘要,提炼知识块,语义简练,提升检索效果;然后生成阶段又用的知识块原文,保证了生成的质量。
子问题检索
用大模型针对知识块生成几个子问题,数据库中就存储生成的子问题;在生成阶段,用用户提示词中的问题去找到相似/相对应的子问题,然后同样,映射到原知识块,生成回答。
句子窗口检索
切割成最小语义知识块,检索时拼接前后文档,一定程度减少歧义;生成阶段根据拼接的文档去生成回答。
多路召回

平滑得分:RRF算法(指数也可以自己设置)
Rerank

右边每个分数对应的每个文档的相关性得分
去重目的:rerank模型比较耗费资源,粗筛以提升响应速率
Cross-Encoder模型
生成优化的技巧
如何利用众多参考文档?
refine模式
一个一个地去给大模型输送所有参考文档,得到最终答案。
成本高
多文档场景下的refine模式
相比于refine模式,多一个输送前的打包步骤
tree_summarize

将后面的答案当做参考文档继续输送。
改写提问
原因:提问不规范、多轮对话、复杂提问均可能为改写原因
| 特征/需求 | 基于规则的改写 | 基于模型的改写 |
|---|---|---|
| 问题复杂度 | 简单、规则明确的情况 | 复杂、多样化的问题 |
| 可控性 | 高,可精确控制 | 低,可自由生成,但可能不完全可控 |
| 计算资源 | 低,快速 | 高,需要更多计算资源 |
| 灵活性 | 低,规则固定 | 高,可以处理各种变体 |
| 应用场景 | 实时性高、规则化强的场景(如FAQ、客服机器人) | 自然对话系统、多领域应用、复杂问题求解 |
也可以给用户提供提问模板
合理利用元数据
• 什么是元数据:对文档的描述,如类型、作者、创建日期、来源等
• 检索前过滤:如:剔除无关文档、检索最近文档
• 检索中评估相关性:如:重要文档给予更高的权重加成
• 检索后重排:如:重要文档排前面
• 生成时提升用户体验:提供参考文档来源,增加可信度
示例问题:我问你房价是多少
如何评估RAG
量化成效,快速迭代
RAG的评估指标
• 准确率:直接站在用户视角,看答案是否符合实际情况
• 忠实度:生成的内容是否忠实于提供的上下文或背景信息
• 召回率、精确率、F1:评估参考文档有没有准确的、完整的给找出来
RAG的评估方法
01 人工评估
准备测试样本,包含问题、标准答案、评分标准
执行测试,得到作答结果
人工交叉评估,评估每个回答准确or错误,或者对每个回答评分
统计准确率,或者统计得分
02 模型自动评估
准备测试样本,包含问题、标准答案
执行测试,得到作答结果
模型评估方法1:将问题+作答结果输入Cross-Encoder模型,得到两者的相关性作为得分
模型评估方法2:评估标准答案和作答结果的文本相似度,得到结果作为评分
统计得分
可以用人工评估也可以用模型评估
善用工具
评估框架: LangSmith、Langfuse、RADS……
RAGvs微调
| 对比维度 | RAG(检索增强生成) | 微调(Fine-tuning) |
|---|---|---|
| 核心原理 | 外部知识库检索 + LLM生成 | 直接修改模型权重,学习数据知识 |
| 知识更新 | 随时增删改知识库,实时更新 | 需重新训练,更新成本高、周期长 |
| 数据量要求 | 少量文档即可,无需大量数据 | 需要大量高质量标注数据 |
| 计算资源 | 低,主要是检索开销 | 高,需要GPU/显存,训练耗时 |
| 幻觉(hallucination) | 低,答案基于检索事实 | 可能产生幻觉,依赖训练数据质量 |
| 可控性 | 高,可溯源、可引用来源 | 低,生成过程不可控 |
| 适用场景 | 知识频繁更新、需要可解释、知识库大 | 固定领域、风格对齐、能力增强 |
| 部署成本 | 低,易维护 | 高,需持续训练与部署 |
相关英文翻译:
• 切分前的知识文档:document
• 切分后的知识块:chunk
• 用户的提问:query
• 模型检索出来的结果:context
• 模型的回答:response



